 Contemporary Monochrome Exhibition Wall Art Midjourney 7 Prompt PDF Guide
Contemporary Monochrome Exhibition Wall Art Midjourney 7 Prompt PDF Guide  Photographic Vintage Album Cover Midjourney Prompt PDF Guide + BONUS
Photographic Vintage Album Cover Midjourney Prompt PDF Guide + BONUS  Unreal Artifacts of the Alternative Past Midjourney Prompt
Unreal Artifacts of the Alternative Past Midjourney Prompt  Midjourney Prompts for Dynamic Photorealism on Black White Rays PDF Guide
Midjourney Prompts for Dynamic Photorealism on Black White Rays PDF Guide The artificial intelligence community is once again grappling with concerns over data provenance in large language model (LLM) training. The latest focus is on Chinese AI lab DeepSeek and its new reasoning model, DeepSeek R1. Developers and researchers harbor significant suspicions that DeepSeek R1 may have used Google Gemini’s outputs during its training process.
These concerns arose after an analysis by developer Sam Peich. Peich discovered striking similarities in the phrasing and expressions used by R1-0528, closely mirroring those characteristic of Google Gemini 2.5 Pro. This observation suggests DeepSeek might have shifted from potentially using OpenAI’s synthetic data to data generated by Gemini.
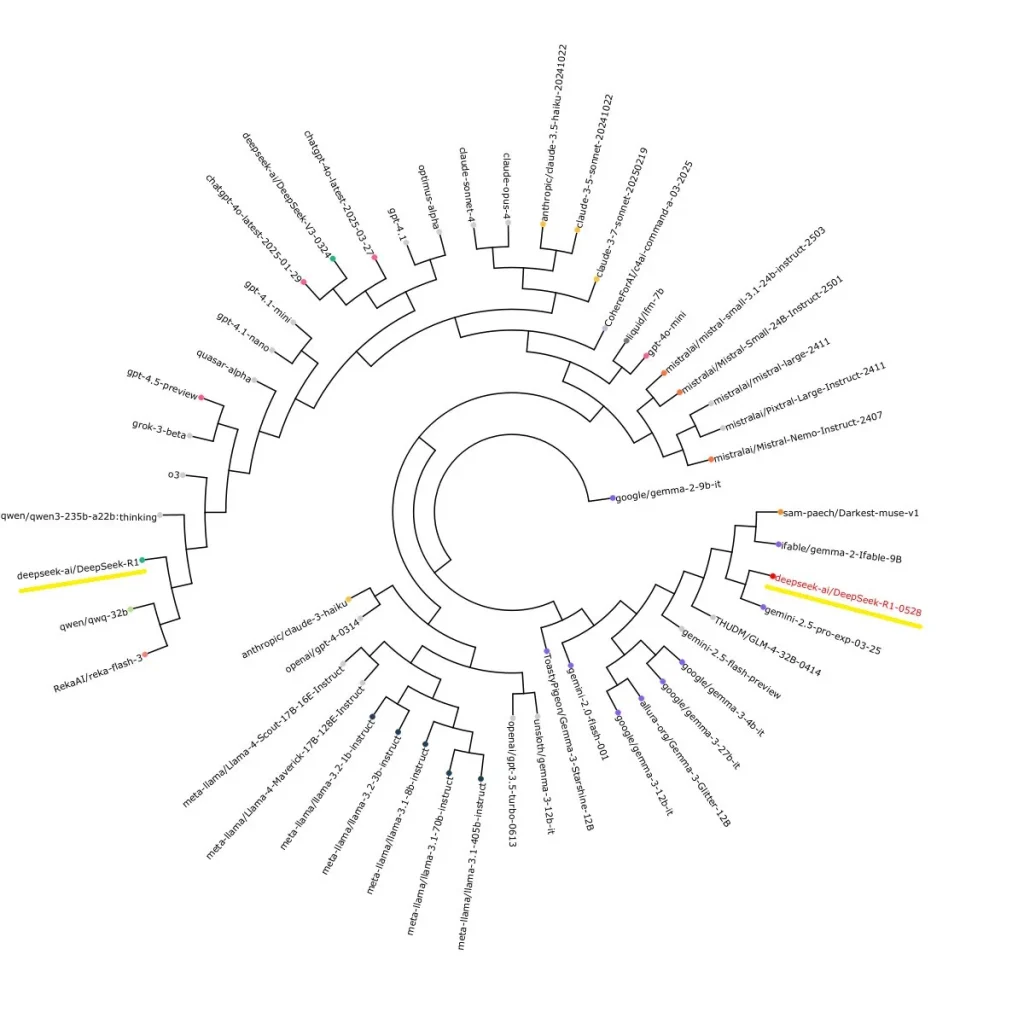
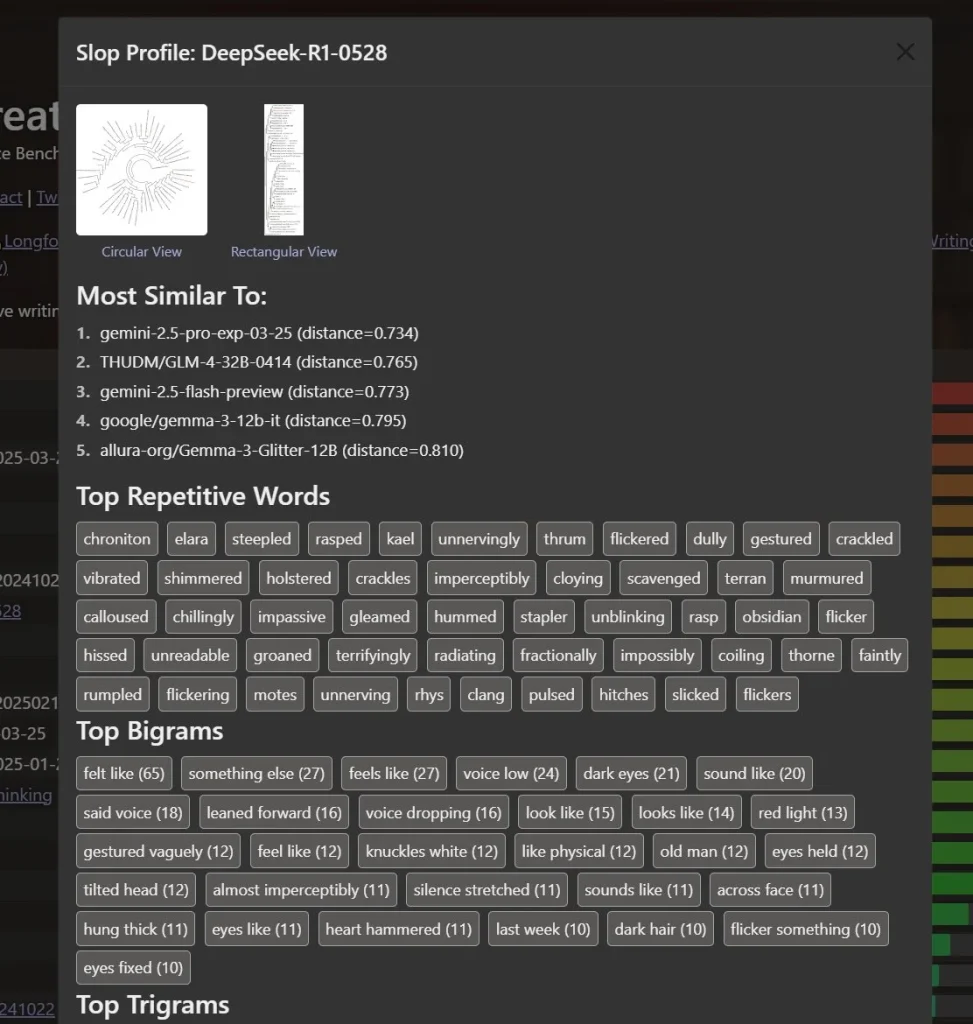
Another researcher also noted that the “traces” (reasoning steps) of the new DeepSeek model strongly resemble Gemini’s logic. Such coincidences raise questions about DeepSeek’s training methodology and the ethics of utilizing external data without proper authorization.
This isn’t the first time DeepSeek has faced such accusations. Previously, their V3 model reportedly identified itself as ChatGPT, hinting at training on OpenAI chat logs. Incidents like these underscore the growing problem of data “contamination” in AI training and highlight the need for stricter regulations and transparency.
In response to these challenges, leading AI companies like OpenAI, Google, and Anthropic are actively developing and implementing measures to protect their models’ output data. These measures include ID verification and trace summarization, which help track and prevent unauthorized use of their data for training competing models.
The DeepSeek R1 situation reignites crucial discussions about competition in the AI sector, data intellectual property rights, and the necessity of establishing transparent and ethical model training practices. As AI becomes increasingly powerful and ubiquitous, these issues will only intensify, demanding careful consideration and collaborative solutions from the entire AI community.





